Qwen3 数学推理评测中的答案格式敏感性
作者: Hejian Sang, Yuanda Xu, Zhengze Zhou, Ran He, Zhipeng Wang
背景
我们一直在基于 DAPO-Math-17k 数据集的指令格式构建数学推理 RL 训练流程。DAPO 格式会在每道题后附加 "Answer: $Answer" 这条指令,并通过正则匹配该模式从模型输出中抽取答案。当我们在非 thinking 模式下评测 Qwen3 基座模型(4B、8B、14B、32B)在 MATH-500、AIME 2024 和 AIME 2025 上的表现时,发现准确率明显低于 Qwen3 技术报告中的结果。在 MATH-500 上,这一差距达到 20 到 40 多个百分点,已经不能简单归因于采样方差或实现细节差异。
我们的假设很直接:Qwen3 模型在微调后倾向于把最终答案放进 \boxed{} 中,即使没有明确要求这种格式;而 Answer: 的正则抽取方式会漏掉一部分本来正确的回答。如果成立,那么复现误差至少有一部分来自评测流程,而不是模型能力本身。
为了验证这一点并量化影响,我们设计了一个只改变指令格式和奖励抽取函数的对照实验。
实验设计
我们对四个 Qwen3 模型(4B、8B、14B、32B)在三种指令变体和三个基准数据集上做了全交叉评测。三种指令变体分别在原题后追加不同后缀:
- boxed:
"Let's think step by step and output the final answer within \boxed{}." - dapo:
"Solve the following math problem step by step. The last line of your response should be of the form Answer: $Answer (without quotes) where $Answer is the answer to the problem.\n\nRemember to put your answer on its own line after \"Answer:\"." - none: 不追加额外指令,只保留原题。
每种指令变体都配套使用相应的 reward function。boxed 和 none 条件使用 math_reward,它会从 \boxed{} 中提取答案,并用 is_equiv 做等价比较;dapo 条件使用 math_dapo,它通过 Answer: 正则抽取答案,并采用精确字符串匹配。
所有实验都使用相同的采样参数:temperature 0.7、top_p=0.8、top_k=20,每题采样 n=16 次。我们报告 mean@16 accuracy,也就是对每道题 16 个样本的正确率取平均。三个基准数据集 MATH-500、AIME 2024 和 AIME 2025 覆盖了不同难度层级。
结果
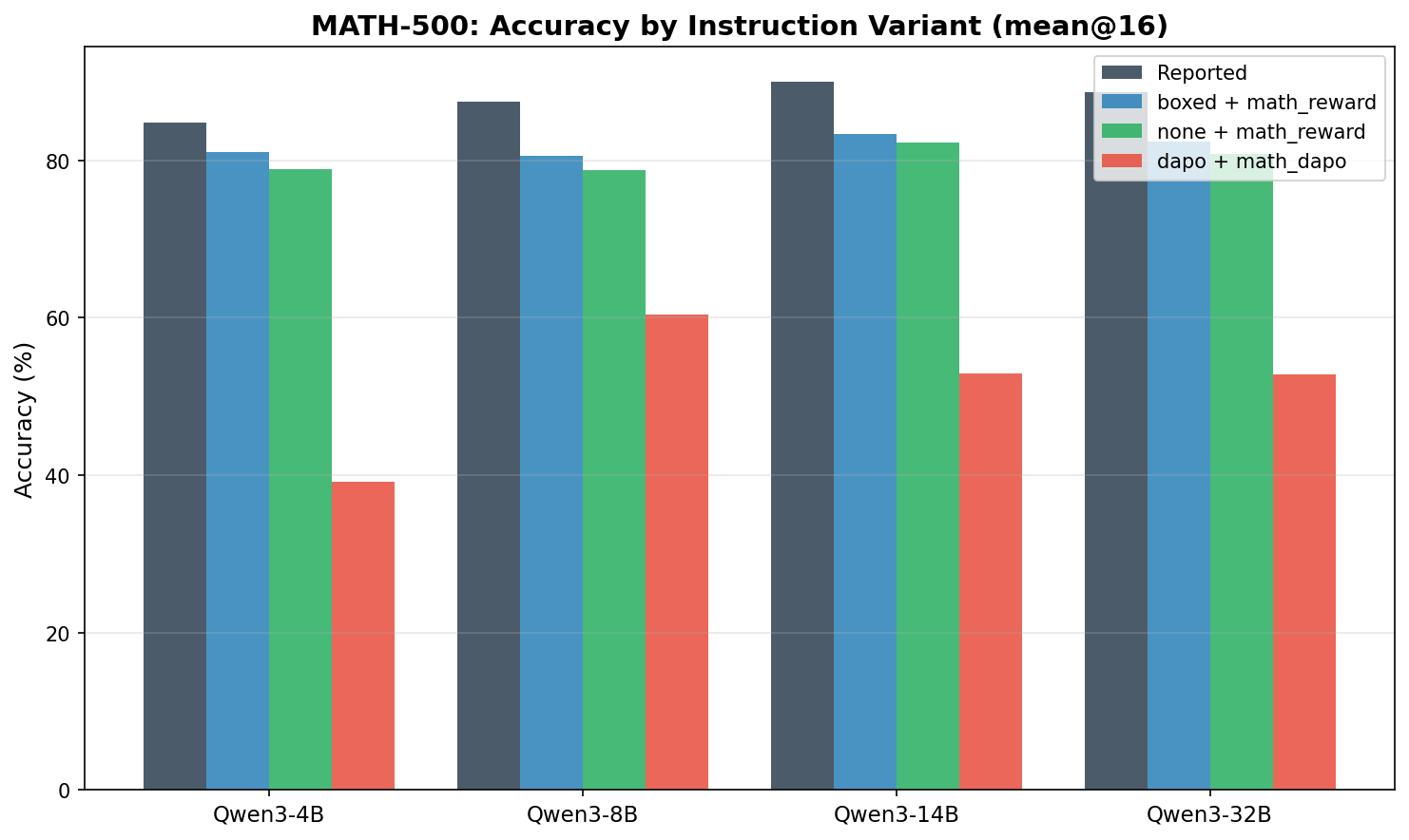
MATH-500
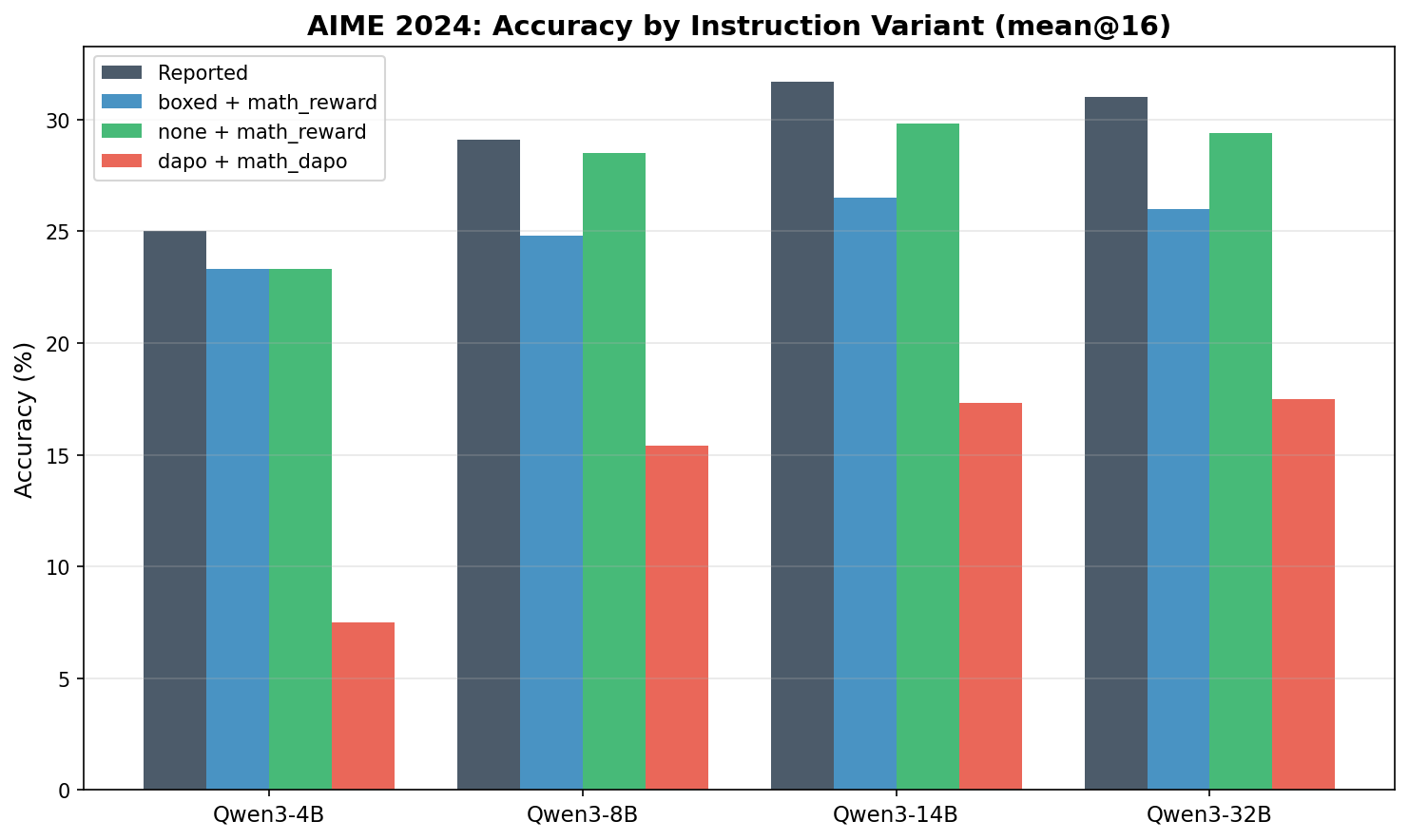
AIME 2024
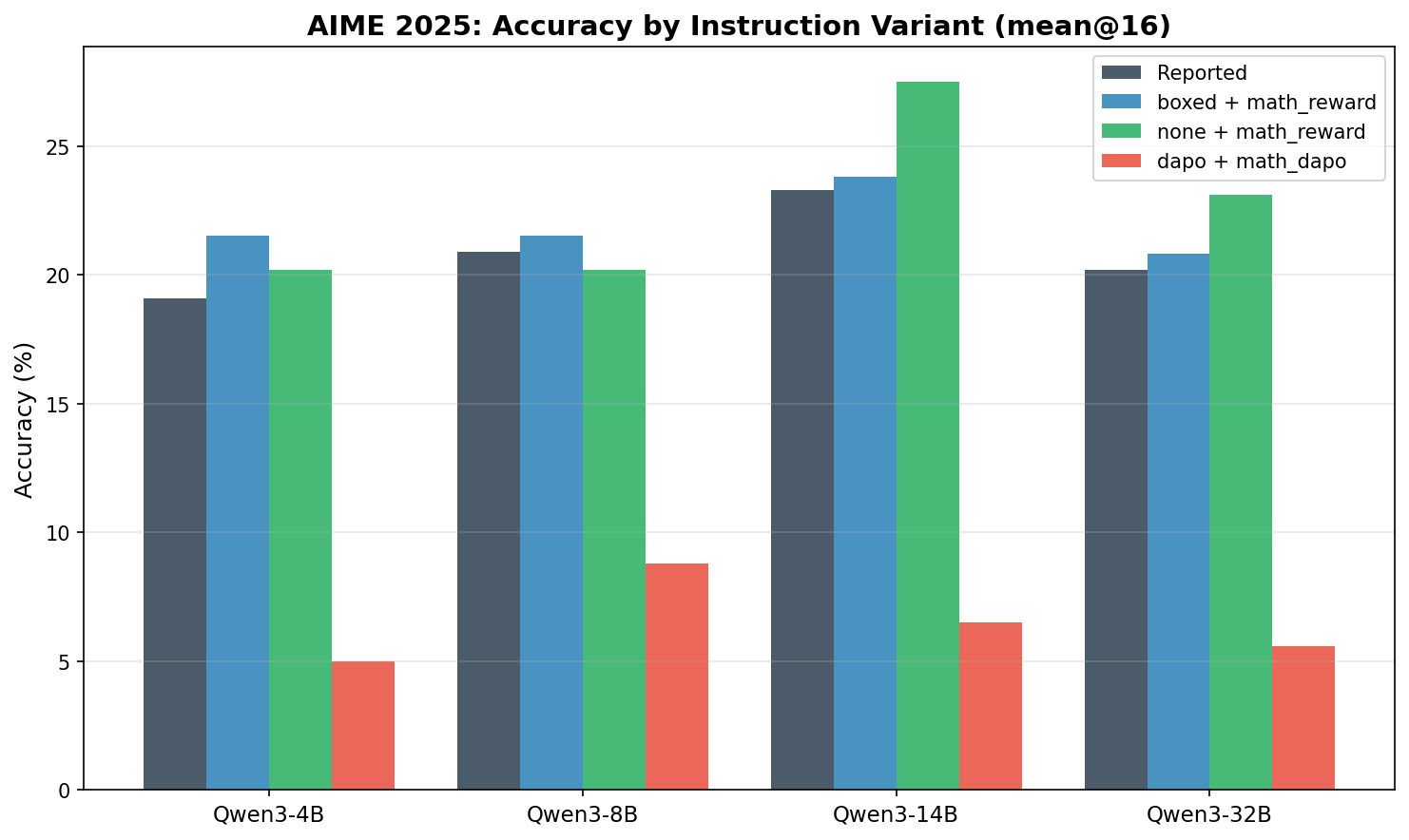
AIME 2025
汇总表
下面的表格汇总了我们的 mean@16 结果,并与 Qwen3 技术报告中的结果做对比。
| Model | Instruction | MATH-500 | AIME’24 | AIME’25 |
|---|---|---|---|---|
| Qwen3-4B | reported | 84.8 | 25.0 | 19.1 |
| Qwen3-4B | boxed | 81.0 | 23.3 | 21.5 |
| Qwen3-4B | none | 78.9 | 23.3 | 20.2 |
| Qwen3-4B | dapo | 39.1 | 7.5 | 5.0 |
| Qwen3-8B | reported | 87.4 | 29.1 | 20.9 |
| Qwen3-8B | boxed | 80.5 | 24.8 | 21.5 |
| Qwen3-8B | none | 78.7 | 28.5 | 20.2 |
| Qwen3-8B | dapo | 60.4 | 15.4 | 8.8 |
| Qwen3-14B | reported | 90.0 | 31.7 | 23.3 |
| Qwen3-14B | boxed | 83.3 | 26.5 | 23.8 |
| Qwen3-14B | none | 82.3 | 29.8 | 27.5 |
| Qwen3-14B | dapo | 52.9 | 17.3 | 6.5 |
| Qwen3-32B | reported | 88.6 | 31.0 | 20.2 |
| Qwen3-32B | boxed | 82.4 | 26.0 | 20.8 |
| Qwen3-32B | none | 80.8 | 29.4 | 23.1 |
| Qwen3-32B | dapo | 52.8 | 17.5 | 5.6 |
分析
发现 1:DAPO 指令格式会导致灾难性的准确率下降
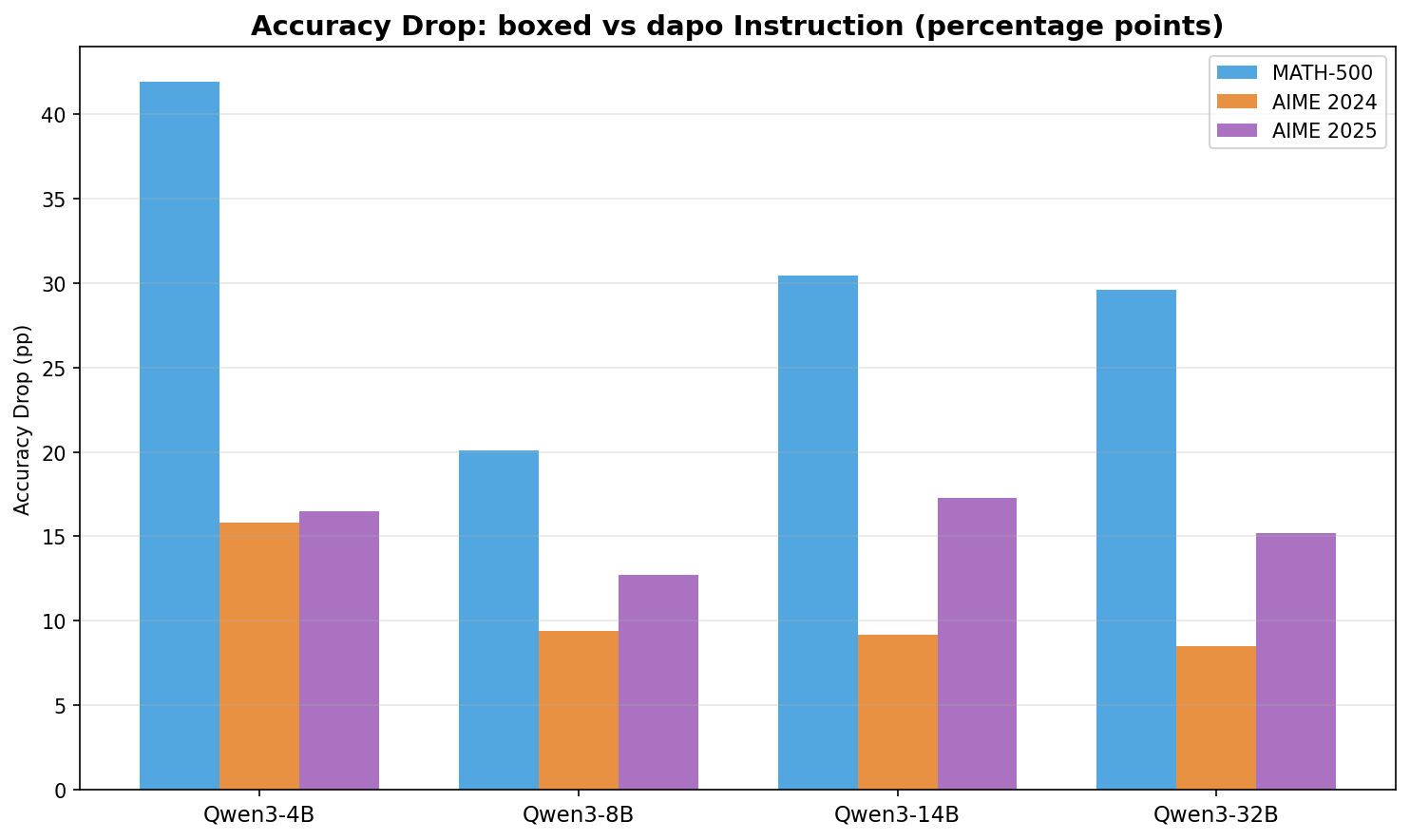
从 boxed 条件切换到 DAPO 条件后,MATH-500 上所有模型规模都出现了明显的准确率下滑,下降幅度从 20 个百分点(Qwen3-8B)到 42 个百分点(Qwen3-4B)不等。在 AIME 基准上,这种下降同样严重:例如 Qwen3-4B 在 AIME’24 上从 23.3% 降到 7.5%,在 AIME’25 上从 21.5% 降到 5.0%。由于这个对比同时改变了输出指令和评分规则,因此它说明 DAPO 评测设置是结果偏差的主要来源,但还不能完全区分其中有多少来自抽取失败,有多少来自指令本身对推理能力的干扰。
发现 2:Qwen3 在没有显式要求时也会默认输出 \boxed{}
boxed 和 none 两个条件的结果在所有模型和数据集上都很接近。在 MATH-500 上,两者最大差距只有 2.1 个百分点(Qwen3-4B: 81.0% vs 78.9%)。这和一个直觉一致:Qwen3 模型默认就偏向把答案写进 \boxed{} 里,即使没有明确说明。额外给出 \boxed{} 指令只带来了很小的提升。
发现 3:在 MATH-500 上,与报告值相比仍然存在少量差距
我们的 boxed 和 none 结果在 MATH-500 上仍然比 Qwen3 技术报告低 3 到 7 个百分点。报告使用的是 mean@64,而我们使用的是 mean@16,因此在随机采样解码下出现小幅差异是合理的,尤其考虑到我们的 GPU 预算限制。剩余差距可能来自采样方差,以及 chat template、system prompt、后处理等设置上的差别。在 AIME 上,我们的结果在一些配置中已经接近甚至超过报告值,不过由于 mean@16 和 mean@64 并不是完全相同的估计量,这些对比仍然需要谨慎解释。
发现 4:AIME 在不加额外指令时略有优势
在 AIME 数据集上,一个有意思的现象是 none 条件在若干情况下能匹配甚至超过 boxed。比如 Qwen3-8B 在 AIME’24 上 none 为 28.5%,而 boxed 为 24.8%;Qwen3-14B 在 AIME’25 上 none 为 27.5%,而 boxed 为 23.8%。一种可能解释是,额外的格式指令会让模型把部分注意力放到格式遵循上,而不是纯粹的数学推理上。不过这些差异整体不大,而且在不同模型上并不完全一致,因此不应过度解读。
发现 5:格式敏感性在不同模型规模上都一致存在
无论是 4B 还是 32B,整体模式都一致:dapo 远低于 boxed 和 none,而 boxed 与 none 彼此接近。这说明问题并不是某个特定模型规模的特例,而是 Qwen3 在这种评测设置下普遍存在的行为模式。换句话说,DAPO 指令格式对于 Qwen3 评测来说是系统性不合适的。
DAPO 结果的损失分析
为了进一步理解 DAPO 为什么会失败,我们把错误拆成两类来源:抽取不匹配,以及指令引起的推理退化。
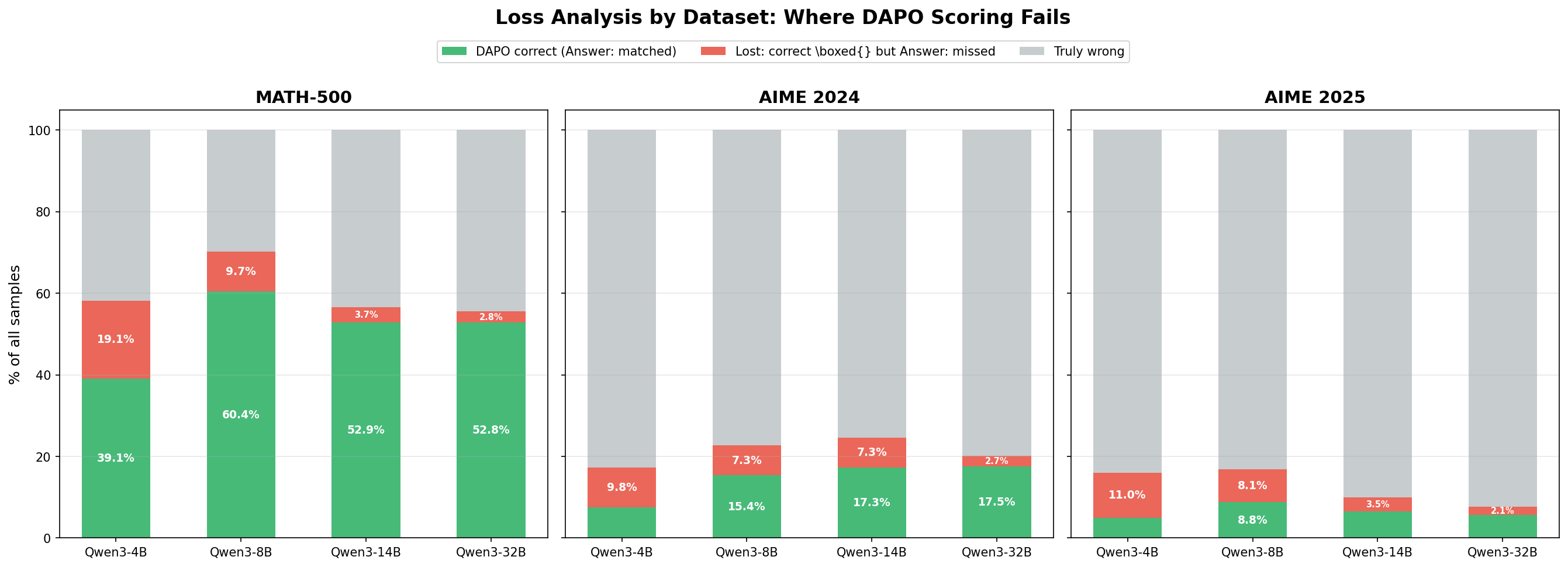
一个关键指标是:模型实际上已经在 \boxed{} 中给出了正确答案,但 Answer: 抽取规则没有抓到它的样本占比。
- Qwen3-4B: 18.1% 的全部样本本来答对了,但被
Answer:抽取器误判为错误 - Qwen3-8B: 9.5% 的样本损失来自抽取不匹配
- Qwen3-14B: 3.9% 的样本损失来自抽取不匹配
- Qwen3-32B: 2.7% 的样本损失来自抽取不匹配
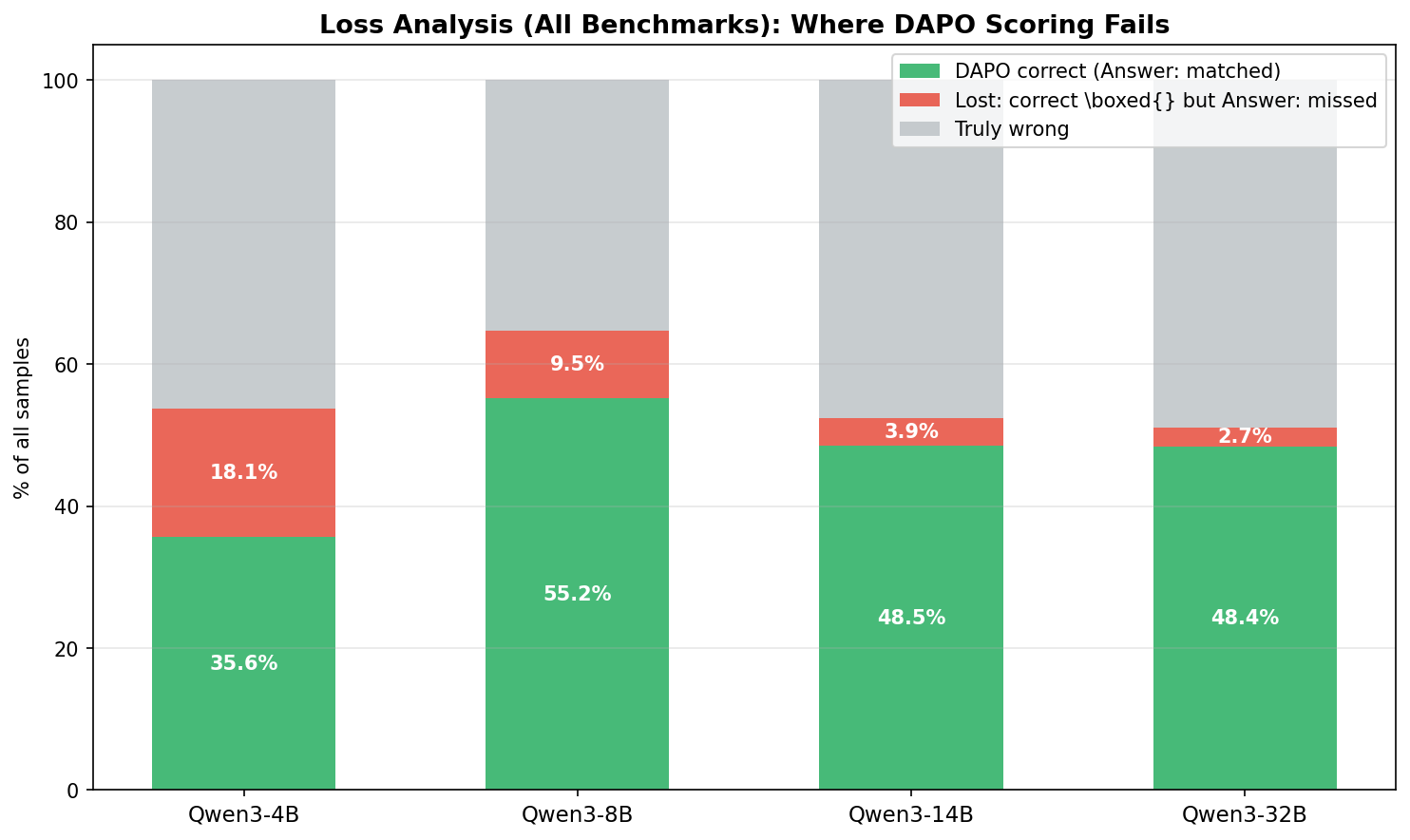
这个分解给出两个重要结论。第一,抽取不匹配只是退化来源之一,而且往往不是最大的那部分。如果把这些“格式没对上但答案其实是对的”样本补回来,那么所有 benchmark 上的修正后综合准确率会分别从 35.6%、55.2%、48.5%、48.4% 提升到 53.7%、64.8%、52.4%、51.1%。但这些修正后结果依然明显低于 boxed 条件,这说明 DAPO 设置除了抽取失败之外,还会带来额外的性能损失。
第二,抽取损失率和模型规模呈负相关。Qwen3-4B 有 18.1% 的样本损失于格式不匹配,而 Qwen3-32B 只有 2.7%。这说明小模型更难适应不熟悉的 Answer: 指令,因此更容易回到自己默认的 \boxed{} 输出形式。更大的模型虽然仍明显偏向 \boxed{},但在按照要求切换输出格式上稍微更强一些。
结论
DAPO 评测流程与 Qwen3 微调后答案输出格式之间的不匹配,是我们无法复现 benchmark 结果的主要原因。Answer: 正则抽取会漏掉那些被放进 \boxed{} 的正确答案,而 DAPO 指令格式本身看起来也会削弱推理表现。使用与 \boxed{} 对齐的评测方式后,我们的结果就明显更接近 Qwen3 技术报告;MATH-500 上剩余的 3 到 7 个百分点差距,基本可以由 mean@16 与 mean@64 的差别以及其他评测设置差异来解释。
参考文献
- Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. (2025). Qwen3 Technical Report. arXiv preprint arXiv:2505.09388.
- Yu, Q., Zhang, Z., Zhu, R., Yuan, Y., Zuo, X., Yue, Y., Dai, W., Fan, T., Liu, G., Liu, L., et al. (2025). DAPO: An Open-Source LLM Reinforcement Learning System at Scale. arXiv preprint arXiv:2503.14476.
如何引用这篇博客
@article{sang2026qwen3formatzh,
title={Qwen3 数学推理评测中的答案格式敏感性},
author={Sang, Hejian and Xu, Yuanda and Zhou, Zhengze and He, Ran and Wang, Zhipeng},
journal={Hejian Blog},
year={2026},
url={https://hjsang.github.io/qwen3-answer-format-sensitivity-zh/}
}
Comments
Readers can comment and reply through GitHub Discussions.
Comments are scaffolded, but GitHub Discussions still needs to be enabled for this repository.
After enabling Discussions, add the Giscus discussion category ID in
_config.ymland switchenabledtotrue.