Answer Format Sensitivity in Qwen3 Math Reasoning Evaluation
Authors: Hejian Sang, Yuanda Xu, Zhengze Zhou, Ran He, Zhipeng Wang
Motivation
We have been building a math reasoning RL training pipeline using the DAPO-Math-17k dataset’s instruction format. The DAPO format appends the instruction "Answer: $Answer" to each prompt, and answers are extracted from model outputs via regex matching against this pattern. When we evaluated Qwen3 base models (4B, 8B, 14B, 32B) in non-thinking mode on MATH-500, AIME 2024, and AIME 2025, we observed accuracy numbers far below those reported in the Qwen3 technical report. On MATH-500, the gaps ranged from 20 to over 40 percentage points, which was too large to attribute to sampling variance or minor implementation differences.
Our hypothesis was straightforward: Qwen3 models have been fine-tuned to place their final answers inside \boxed{} even when no explicit formatting instruction is given, and the Answer: regex extraction pattern misses some of these correct responses. If this were the case, then at least part of the discrepancy would come from the evaluation pipeline rather than model capability.
To validate this hypothesis and quantify the effect, we designed a controlled experiment that varies only the instruction format and reward extraction function.
Experiment Design
We evaluated four Qwen3 models (4B, 8B, 14B, 32B) across three instruction variants and three benchmarks in a fully crossed design. The three instruction variants append different suffixes to each math problem:
- boxed:
"Let's think step by step and output the final answer within \boxed{}." - dapo:
"Solve the following math problem step by step. The last line of your response should be of the form Answer: $Answer (without quotes) where $Answer is the answer to the problem.\n\nRemember to put your answer on its own line after \"Answer:\"." - none: No instruction appended.
Each instruction variant was paired with the appropriate reward function: math_reward (which extracts from \boxed{} and uses is_equiv for comparison) was used with the boxed and none conditions, while math_dapo (which extracts via Answer: regex and uses exact string matching) was used with the dapo condition.
All evaluations used identical sampling parameters: temperature 0.7, top_p=0.8, top_k=20, with n=16 samples per problem. We report mean@16 accuracy across all conditions. The three benchmarks, MATH-500, AIME 2024, and AIME 2025, span a range of difficulty levels.
Results
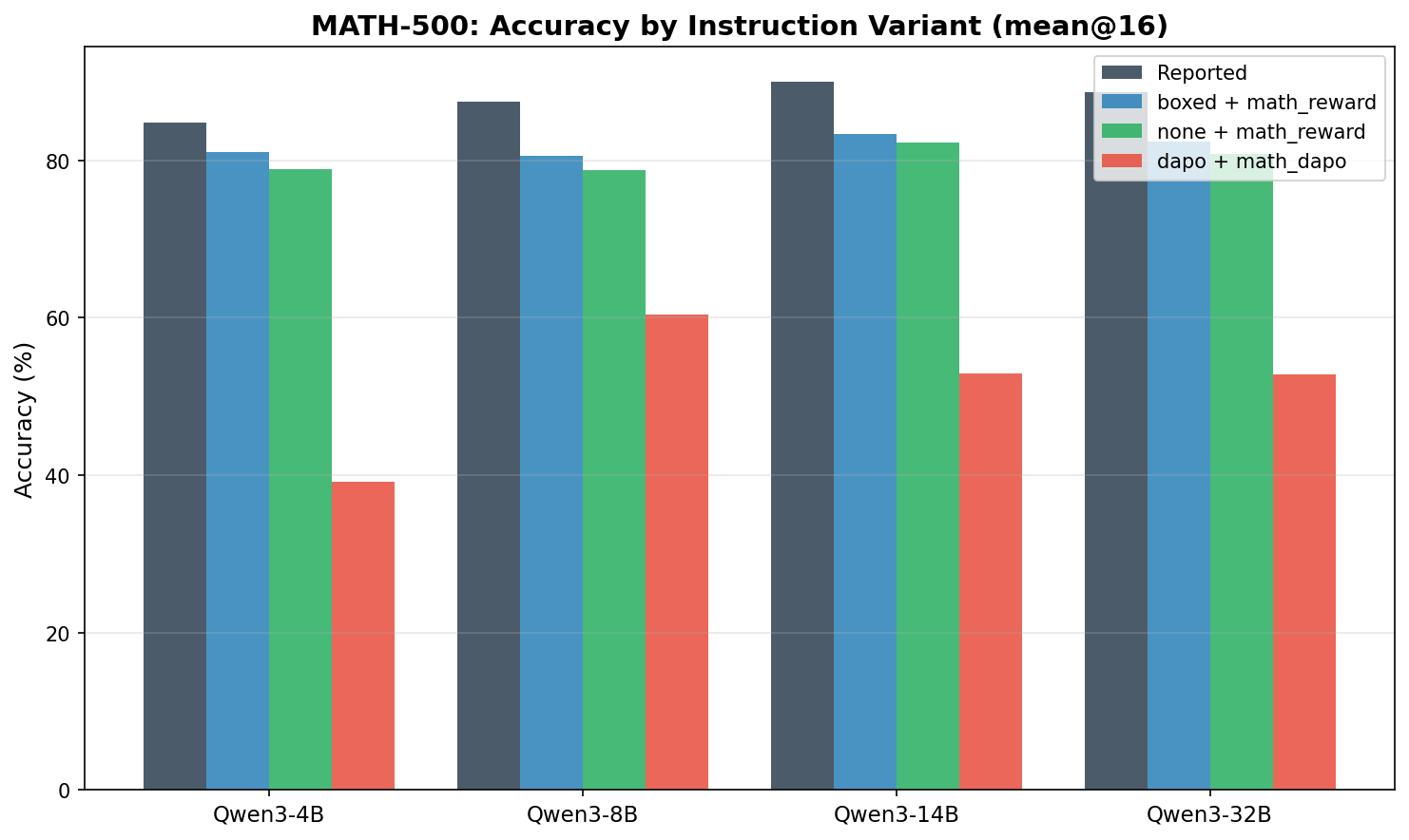
MATH-500
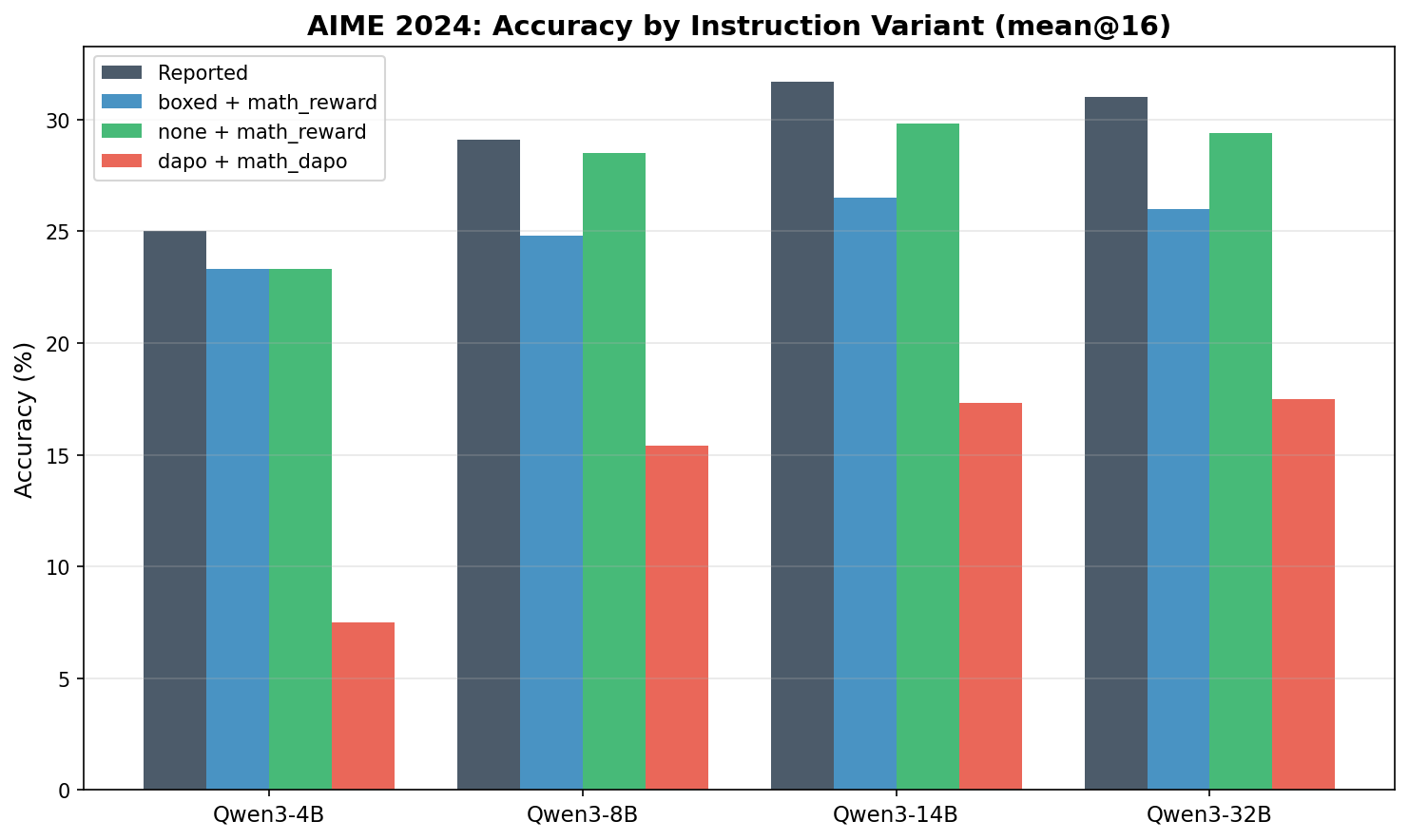
AIME 2024
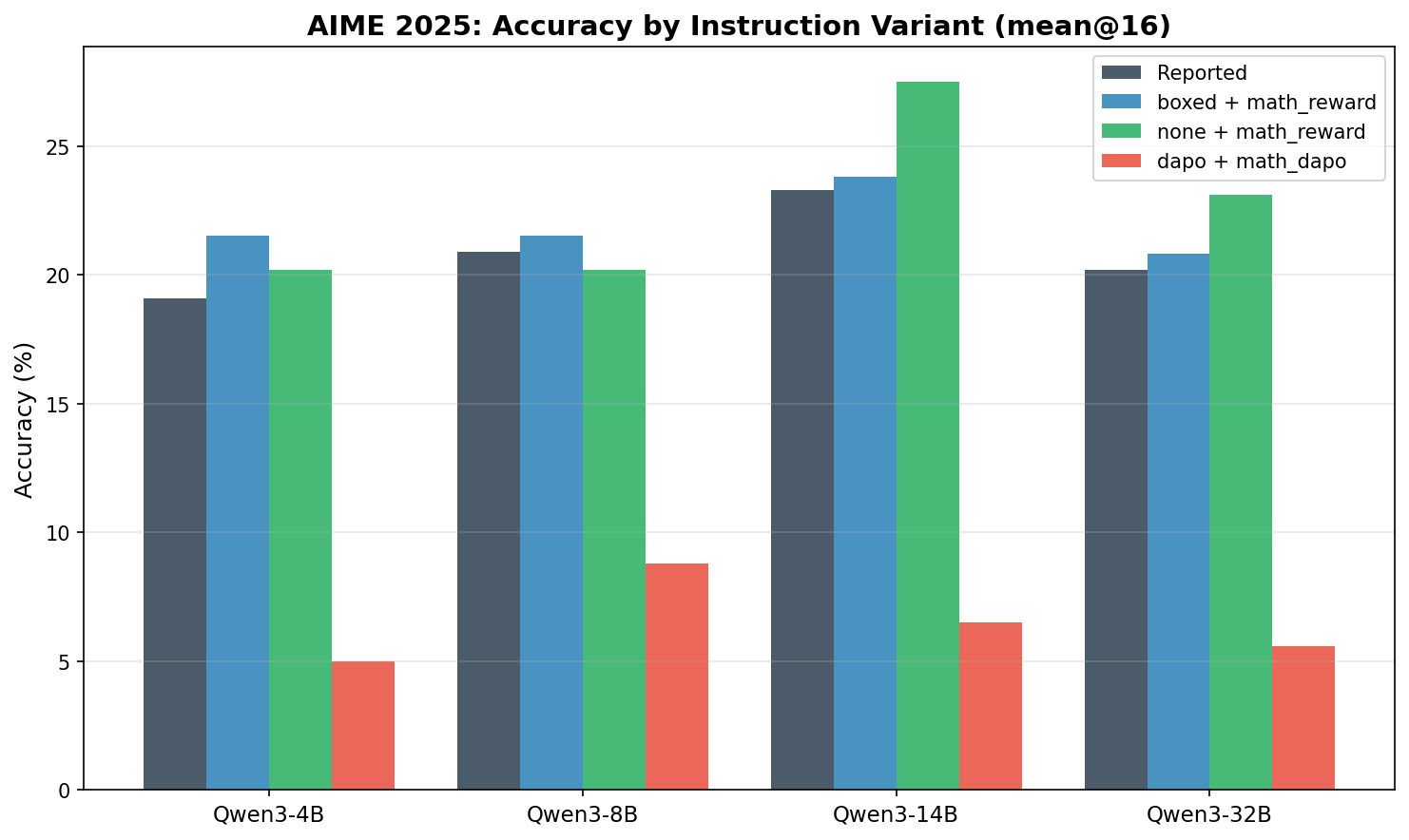
AIME 2025
Summary Table
The following table summarizes our mean@16 results alongside the numbers reported in the Qwen3 technical report.
| Model | Instruction | MATH-500 | AIME’24 | AIME’25 |
|---|---|---|---|---|
| Qwen3-4B | reported | 84.8 | 25.0 | 19.1 |
| Qwen3-4B | boxed | 81.0 | 23.3 | 21.5 |
| Qwen3-4B | none | 78.9 | 23.3 | 20.2 |
| Qwen3-4B | dapo | 39.1 | 7.5 | 5.0 |
| Qwen3-8B | reported | 87.4 | 29.1 | 20.9 |
| Qwen3-8B | boxed | 80.5 | 24.8 | 21.5 |
| Qwen3-8B | none | 78.7 | 28.5 | 20.2 |
| Qwen3-8B | dapo | 60.4 | 15.4 | 8.8 |
| Qwen3-14B | reported | 90.0 | 31.7 | 23.3 |
| Qwen3-14B | boxed | 83.3 | 26.5 | 23.8 |
| Qwen3-14B | none | 82.3 | 29.8 | 27.5 |
| Qwen3-14B | dapo | 52.9 | 17.3 | 6.5 |
| Qwen3-32B | reported | 88.6 | 31.0 | 20.2 |
| Qwen3-32B | boxed | 82.4 | 26.0 | 20.8 |
| Qwen3-32B | none | 80.8 | 29.4 | 23.1 |
| Qwen3-32B | dapo | 52.8 | 17.5 | 5.6 |
Analysis
Finding 1: DAPO instruction format causes catastrophic accuracy drops
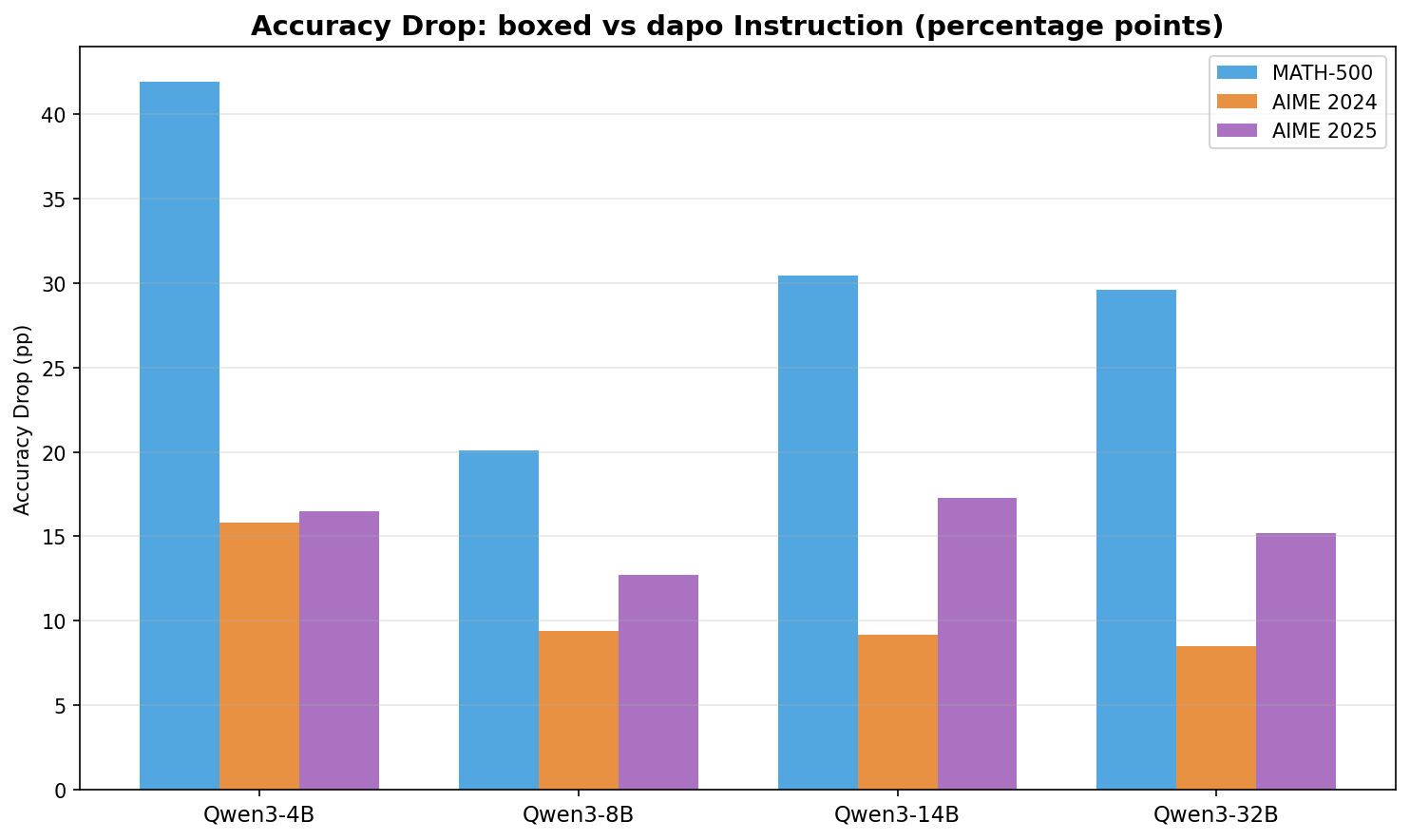
Moving from the boxed setting to the DAPO setting consistently causes large accuracy losses on MATH-500 across all model scales, ranging from 20 pp (Qwen3-8B) to 42 pp (Qwen3-4B). On AIME benchmarks, the drops are similarly severe in relative terms: Qwen3-4B drops from 23.3% to 7.5% on AIME’24, and from 21.5% to 5.0% on AIME’25. Because this comparison changes both the output instruction and the scoring rule, it shows that the DAPO evaluation setting is the primary source of our discrepancy with reported numbers, but does not by itself isolate how much comes from extraction mismatch versus instruction-induced degradation.
Finding 2: Qwen3 defaults to \boxed{} regardless of instruction
The boxed and none conditions produce very similar results across all models and benchmarks. On MATH-500, the gap between boxed and none is at most 2.1 pp (Qwen3-4B: 81.0% vs 78.9%). This is consistent with Qwen3 models having a strong default toward \boxed{} answers even without explicit instruction. Providing an explicit \boxed{} instruction offers only a marginal benefit.
Finding 3: Remaining gap to reported numbers on MATH-500
Our boxed and none results are consistently 3 to 7 percentage points below the Qwen3 technical report numbers on MATH-500. The report uses mean@64 while we use mean@16, so small differences are expected from finite-sample estimation under stochastic decoding, especially given our GPU budget. The remaining gap may therefore reflect a combination of sampling variance and setup differences such as chat template configuration, system prompt, or post-processing. On AIME benchmarks, our numbers are competitive with or exceed reported values in several cases, though those comparisons should also be interpreted with some caution because mean@16 and mean@64 are not exactly identical estimators.
Finding 4: AIME performance benefits slightly from no instruction
An interesting pattern emerges on AIME: in several cases, the none condition matches or outperforms boxed. For Qwen3-8B on AIME’24, none achieves 28.5% vs boxed at 24.8%. For Qwen3-14B on AIME’25, none reaches 27.5% vs boxed at 23.8%. One possible explanation is that the explicit formatting instruction subtly shifts the model’s attention toward format compliance rather than pure mathematical reasoning. The differences are modest and mixed across models, so they should not be overinterpreted given mean@16 sampling on 30-problem AIME sets.
Finding 5: Format sensitivity is consistent across model scales
The relative pattern, dapo far below boxed and none, with boxed and none close together, holds across all four model sizes from 4B to 32B. This rules out the possibility that the issue is specific to a particular model size or capability level. The DAPO instruction format is universally problematic for Qwen3 evaluation.
Loss Analysis of DAPO Results
To understand why DAPO scoring fails, we decompose the errors into two sources: extraction mismatches and instruction-induced reasoning degradation.
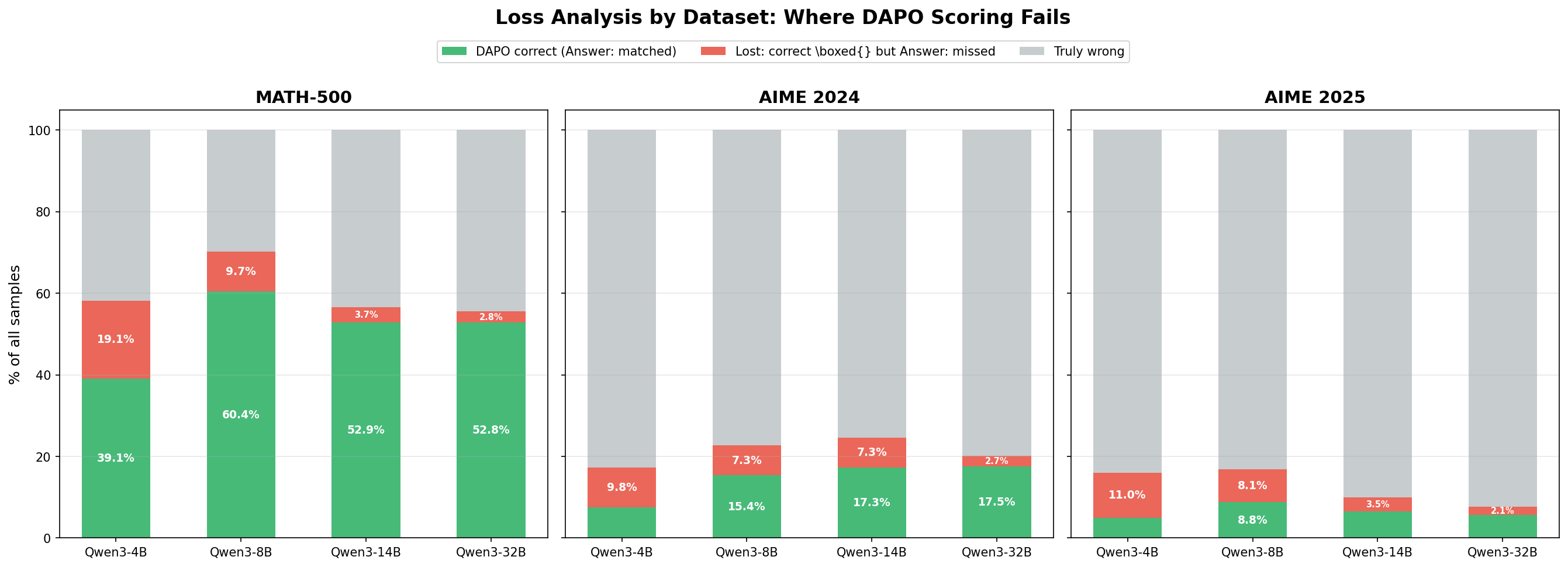
A key metric is the fraction of samples where the model produced the correct answer inside \boxed{} but the Answer: extraction pattern failed to capture it:
- Qwen3-4B: 18.1% of all samples were correctly solved but scored as incorrect by the
Answer:extractor - Qwen3-8B: 9.5% lost to extraction mismatch
- Qwen3-14B: 3.9% lost to extraction mismatch
- Qwen3-32B: 2.7% lost to extraction mismatch
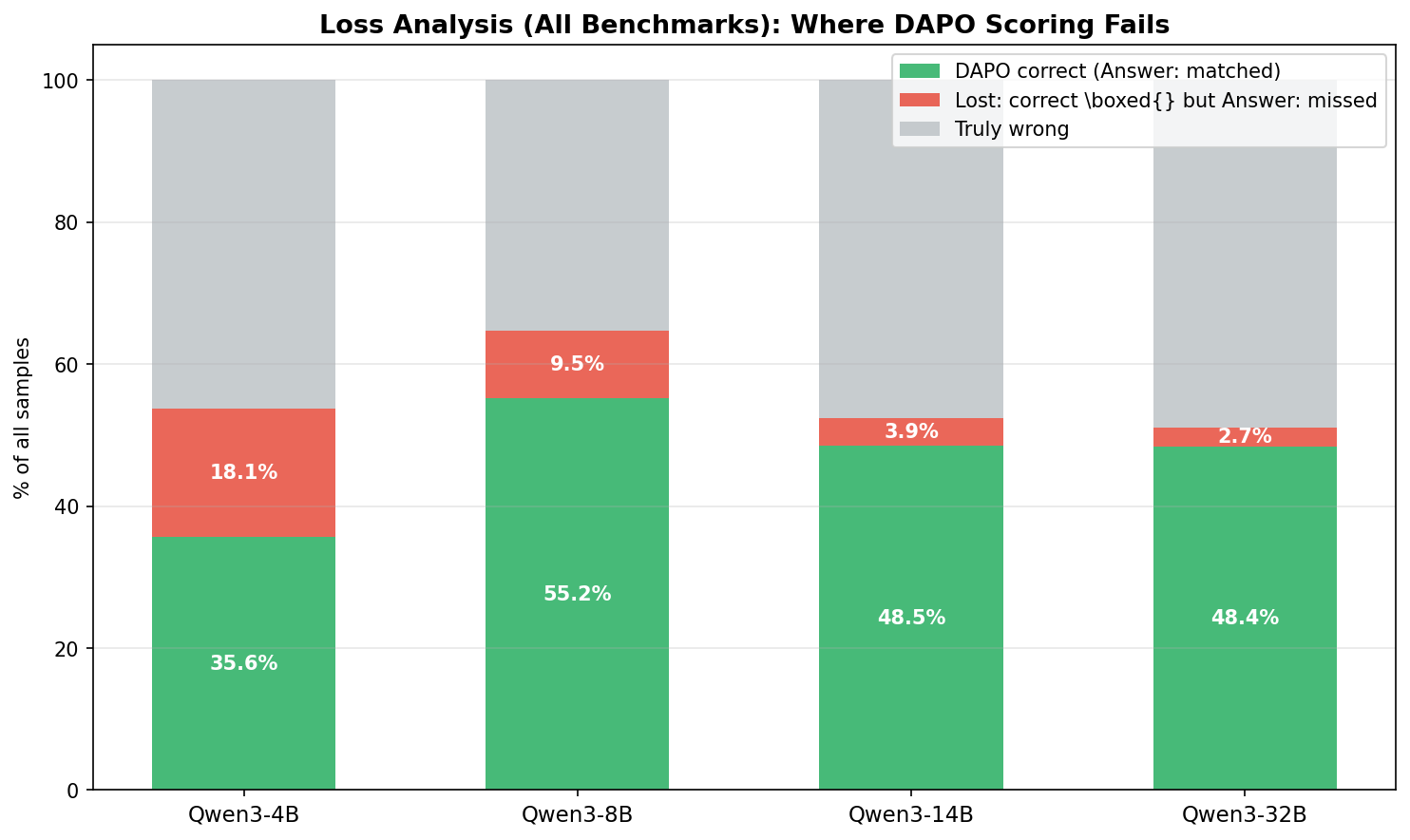
Two insights emerge from this breakdown. First, extraction mismatch is only one of two degradation sources, and often not the larger one. If we rescue the mismatched samples, the corrected combined accuracy across all benchmarks rises to 53.7% for Qwen3-4B, 64.8% for Qwen3-8B, 52.4% for Qwen3-14B, and 51.1% for Qwen3-32B, up from raw DAPO accuracies of 35.6%, 55.2%, 48.5%, and 48.4% respectively. The rescued accuracy still falls well short of boxed-condition performance, which is consistent with the DAPO setting causing additional degradation beyond pure extraction mismatch.
Second, the extraction loss rate is inversely correlated with model size. Qwen3-4B loses 18.1% of samples to format mismatch, while Qwen3-32B loses only 2.7%. This suggests that smaller models are less capable of following the unfamiliar Answer: instruction and default to \boxed{} more frequently. Larger models, while still heavily biased toward \boxed{}, are somewhat better at adapting their output format to match the instruction.
Conclusion
The answer format mismatch between the DAPO evaluation pipeline and Qwen3’s fine-tuned output format is a primary explanation for our inability to reproduce benchmark results. The Answer: regex extraction misses correct answers placed in \boxed{}, and the DAPO instruction format itself also appears to degrade reasoning performance. With \boxed{}-aligned evaluation, our results move much closer to the Qwen3 technical report numbers, with the remaining 3 to 7 percentage point gap on MATH-500 plausibly explained by a mix of mean@16 versus mean@64 differences and other evaluation-setup details.
References
- Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. (2025). Qwen3 Technical Report. arXiv preprint arXiv:2505.09388.
- Yu, Q., Zhang, Z., Zhu, R., Yuan, Y., Zuo, X., Yue, Y., Dai, W., Fan, T., Liu, G., Liu, L., et al. (2025). DAPO: An Open-Source LLM Reinforcement Learning System at Scale. arXiv preprint arXiv:2503.14476.
How To Cite This Blog
@article{sang2026qwen3format,
title={Answer Format Sensitivity in Qwen3 Math Reasoning Evaluation},
author={Sang, Hejian and Xu, Yuanda and Zhou, Zhengze and He, Ran and Wang, Zhipeng},
journal={Hejian Blog},
year={2026},
url={https://hjsang.github.io/qwen3-answer-format-sensitivity/}
}
Comments
Readers can comment and reply through GitHub Discussions.
Comments are scaffolded, but GitHub Discussions still needs to be enabled for this repository.
After enabling Discussions, add the Giscus discussion category ID in
_config.ymland switchenabledtotrue.